版权声明:本文为博主原创文章,转载请注明原文出处!
作者:阿振
写作时间:2024-08-29 09:32:15
C++字符串中文字符处理初探
好久没有写博客了,工作忙得都快忘记自己之前还有写博客的习惯。今天我们简单聊一下C++中如何处理中文字符。学过C++的都知道标准库中的 std::string更像是一个存储着 char的容器,而不是普遍意义上的字符串。而我们的中文字符又无法使用单个 char进行存储。
常见用于中文的的字符编码有 GBK和 UTF-8,UTF-16等,在Windows中文操作系统中,默认字符编码是 GBK使用2个字节存储一个中文字符;而在Linux以及macOS中使用 UTF-8编码。UTF-8编码是一个变长的编码:一个ASCIl字符只需1字节编码;带有变音符号的其他语言文字的字母需要2字节编码;中文以及日韩等一些亚洲文字需要3个字节编码;其他一些极少使用的字符使用4个字节编码。
那C++中的 std::string采用什么编码呢?一般来说,在Windows中文环境下,C++源文件的编码通常为GBK; 在Linux及macOS环境下,默认的为UTF-8 编码。在不依赖第三方库处理C++字符串时,一般可以使用 std::string进行读写,输入和输出;当要进行中文处理的时候,将其转为 std::wstring进行。当然,如果你需要进行复杂的字符串处理,可以通过第三方库例如,ICU、Qt、Poco等,这些第三方库提供了很多强大的功能。
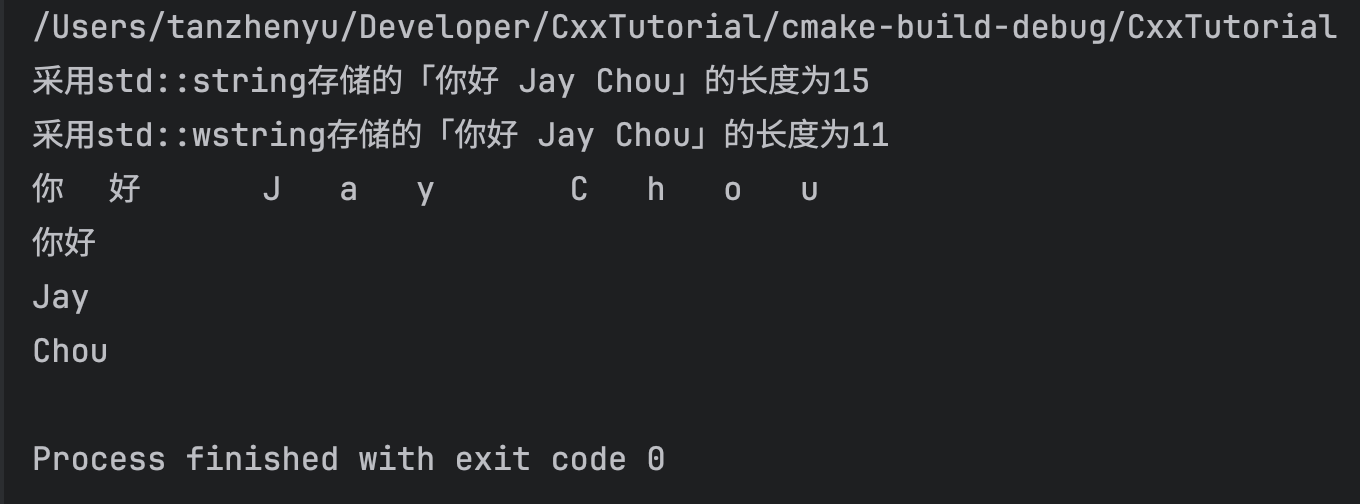
下面程序演示了如何进行两者的转化,最后将转换后的 std::wstring使用空格进行分割输出(程序在macOS上运行通过,在Windows下可能还需要额外工作)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| module;
#include <string>
#include <codecvt>
#include <print>
#include <ranges>
#include <vector>
#include <algorithm>
#include <iostream>
export module CString;
using std::print;
using std::println;
using std::string;
using std::wstring;
using std::vector;
export class Solution {
public:
static void run() {
const string s = "你好 Jay Chou";
println("采用std::string存储的「{}」的长度为{}", s, s.length());
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
const wstring ws = converter.from_bytes(s.data());
println("采用std::wstring存储的「{}」的长度为{}", s, ws.length());
std::setlocale(LC_ALL, "");
for (const auto& c: ws) {
char chars[3] = "";
std::wctomb(chars, c);
print("{}\t", chars);
}
println();
auto tokens = ws |
std::views::split(' ') |
std::ranges::to<vector<wstring>>();
std::ranges::for_each(tokens, [](const auto& token) {
std::wcout << token << std::endl;
});
}
};
|
运行之后的结果如下图: