版权声明:本文为博主原创文章,转载请注明原文出处!
写作时间:2019-03-02 12:46:15
本文部分图片素材来自互联网,如有侵权,请联系作者删除!
最简单的RNN回归模型入门(PyTorch版)
RNN入门介绍
至于RNN的能做什么,擅长什么,这里不赘述。如果不清楚,请先维基一下,那里比我说得更加清楚。
我们首先来来看一张经典的RNN模型示意图!
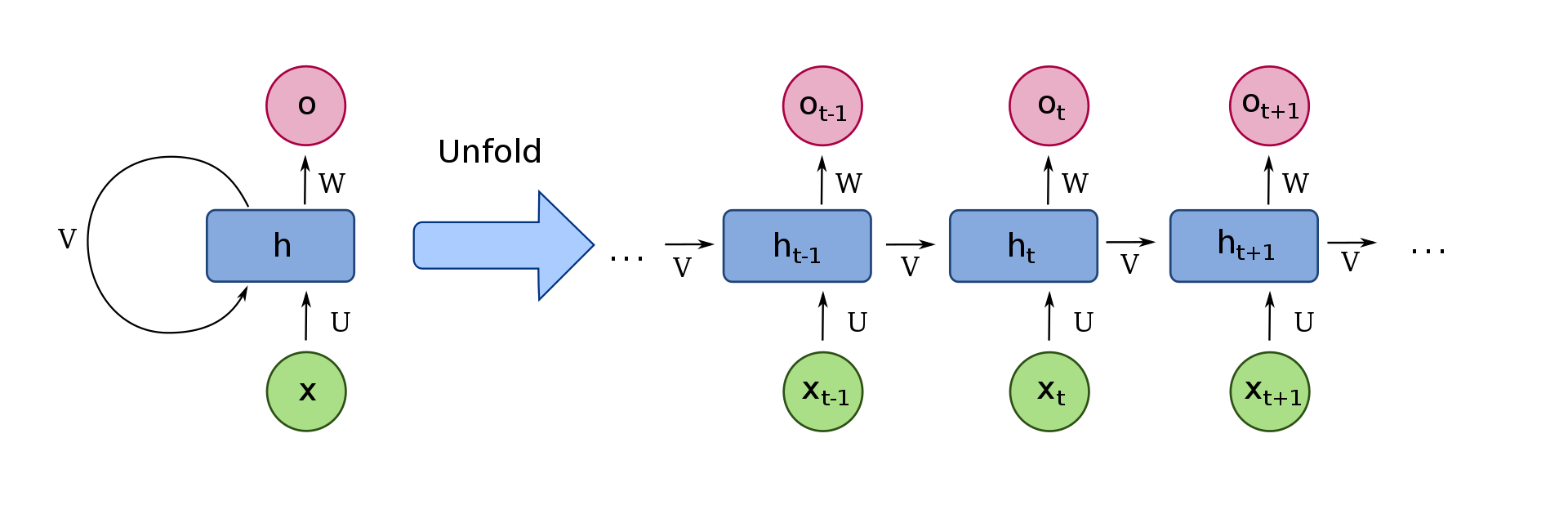
图分左右两边:左边给出的RNN是一个抽象的循环结构,右边是左边RNN展开以后的形式。先来看右边的结构,从下往上依次是序列数据的输入X(图中的绿色结构,可以是时间序列,也可以是文本序列等等)。对于t时刻的x经过一个线性变换(U是变换的权重),然后与t-1时刻经过线性变换V的h相加,再经过一个 非线性激活(一般使用tanh或者relu函数)以后,形成一个t时刻的中间状态h,然后再经过一个线性变换(W)输出o ,最后再经过一个非线性激活(可以是sigmoid函数或者softmax等函数)形成最后的输出y。
上面的文字描述,可以形式化表示为下面的公式:
$$a^t = Vh^{t-1} + Ux^t + b \ h^t=tanh(a^t) \ o^t=Wh^t + c\ y^t=sigmoid(o^t)$$
是不是公式能比文字更加说明问题!
再来说左边的结构,坐标的结构表明后面地展开网络中的U,V,W参数都是在共享的,就是说不管我们的序列有多长,都是共享这一套参数的。这是RNN很重要的一个特性。
RNN的隐藏层可以有多层,但是RNN中我们的隐藏层一般不会设置太多,因为在横向上有很长的序列扩展形成的网络,这部分特征是我们更加关注的。最后,需要说明的是RNN可以是单向的,也可以是双向的。
PyTorch中的RNN
下面我们以一个最简单的回归问题使用正弦sin函数预测余弦cos函数,介绍如何使用PyTorch实现RNN模型。
先来看一下PyTorch中RNN类的原型:

- 必选参数
input_size指定输入序列中单个样本的大小尺寸,比如在NLP中我们可能用用一个10000个长度的向量表示一个单词,则这个input_size就是10000。在咱们的回归案例中,一个序列中包含若干点,而每个点的所代表的函数值(Y)作为一个样本,则咱们案例中的input_size为1。这个参数需要根据自己的实际问题确定。 - 必选参数
hidden_size指的是隐藏层中输出特征的大小,这个是自定义的超参数。 - 必选参数
num_layers指的是纵向的隐藏层的个数,根据实际问题我们一般可以选择1~10层。 - 可选参数
batch_first指定是否将batch_size作为输入输出张量的第一个维度,如果是,则输入的尺寸为(batch_size,seq_length,input_size),否则,默认的顺序是(seq_length,batch_size,input_size)。 - 可选参数
bidirectional指定是否使用双向RNN。
下面再来说说RNN输入输出尺寸的问题,了解了这个可以让我们我们调试代码的时候更加清晰。下面是PyTorch官方的说明:
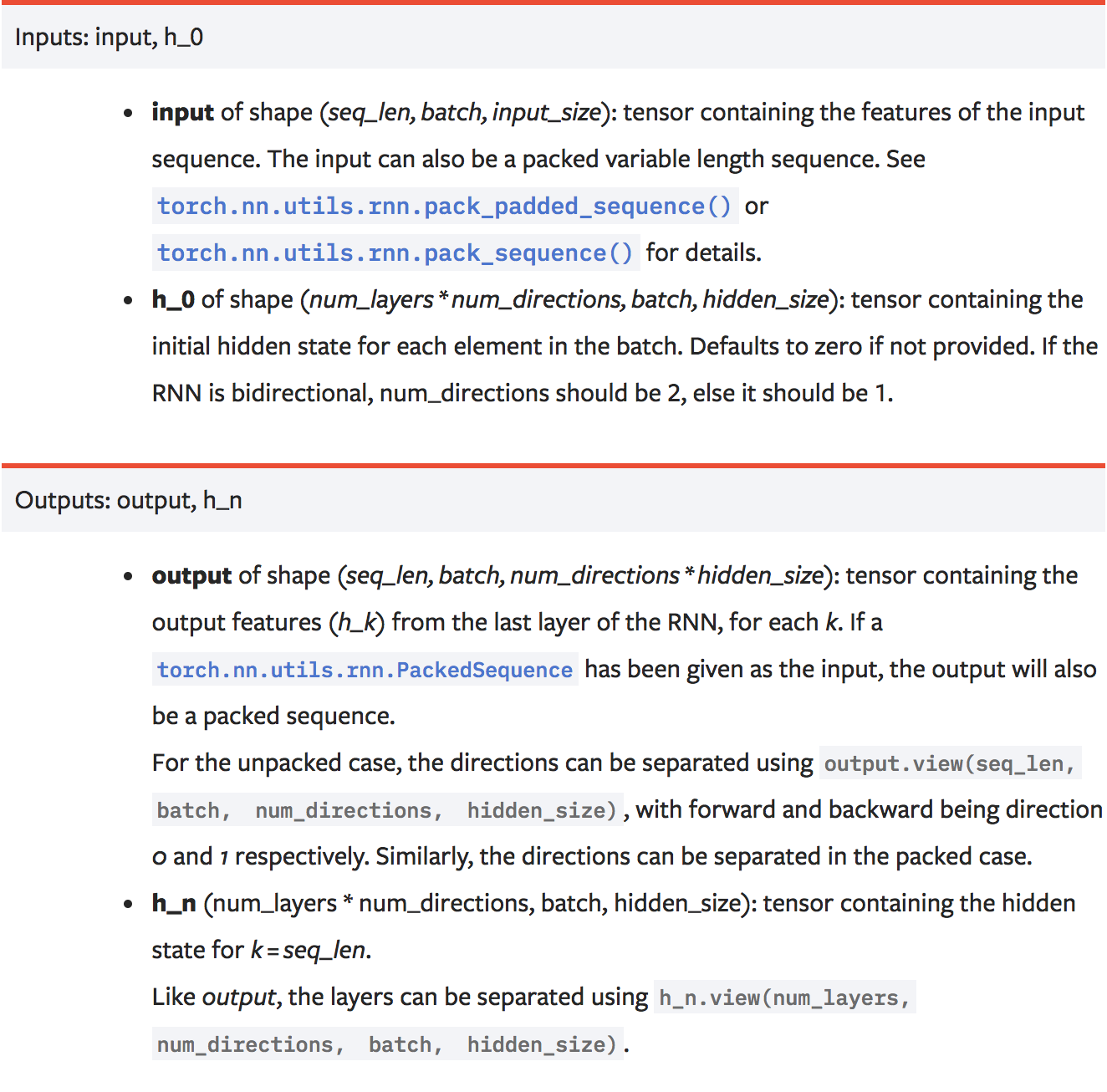
对于RNN的输入包括输入序列和一个初始化的隐藏状态$h_0$。输入序列尺寸默认是(sequence_length,batch_size, input_size),所以如果我们的数据形式不是这样的,则需要手动调整为这种类型的格式。
隐藏状态$h_i$的尺寸是(num_layers * num_directions, batch_size, hidden_size)。单向RNN的num_directions为1,双向RNN的num_directions为2。
他们的尺寸为什么是这样的呢?这得根据本文开头的那个公式计算,即就是矩阵的相乘需要满足矩阵尺寸的关系,聪明的你想明白了吗?
输出的尺寸为 (sequence_length, batch_size, num_directions * hidden_size)
每一次RNN运行结果输出中还会附带输出中间隐藏状态$h_i$,当然这个尺寸和初始的隐藏状态相同。
下面以一个简单的例子说明怎么在程序中查看他们的尺寸:
1 | import torch |
其输出结果如下:
1 | torch.Size([5, 3, 20]) |
这里的weight_ih_l0表示的是RNN隐藏层第一层的权重U,weight_hh_l0表示的隐藏层第一层的权重V,类似的bias开头的表示偏置或者叫增益(我不知道中文如何翻译),以l数字结尾的表示第几层的权重或者偏置。
代码实现与结果分析
好了,搞清楚了RNN的基本原理以及PyTorch中RNN类的输入输出参数要求,我们下面实现我们的回归案例。
比较重要的几个超参数是:TIME_STEP指定输入序列的长度(一个序列中包含的函数值的个数),INPUT_SIZE是1,表示一个序列中的每个样本包含一个函数值。
我们自定义的RNN类包含两个模型:一个nn.RNN层,一个nn.Linear层,注意forward函数的实现,观察每个变量的尺寸(注释中给出了答案)。
1 | import torch |
最后的结果如下:
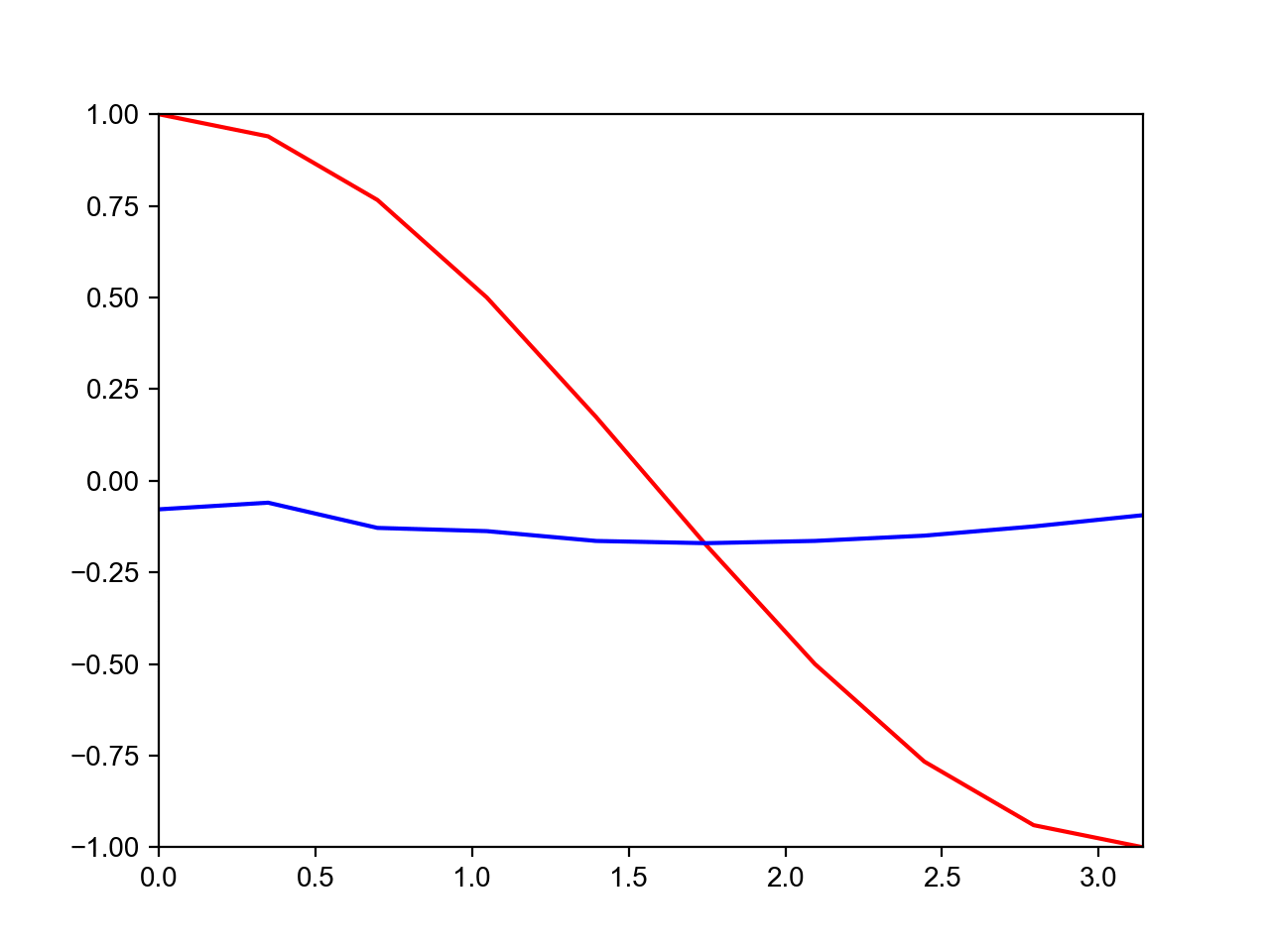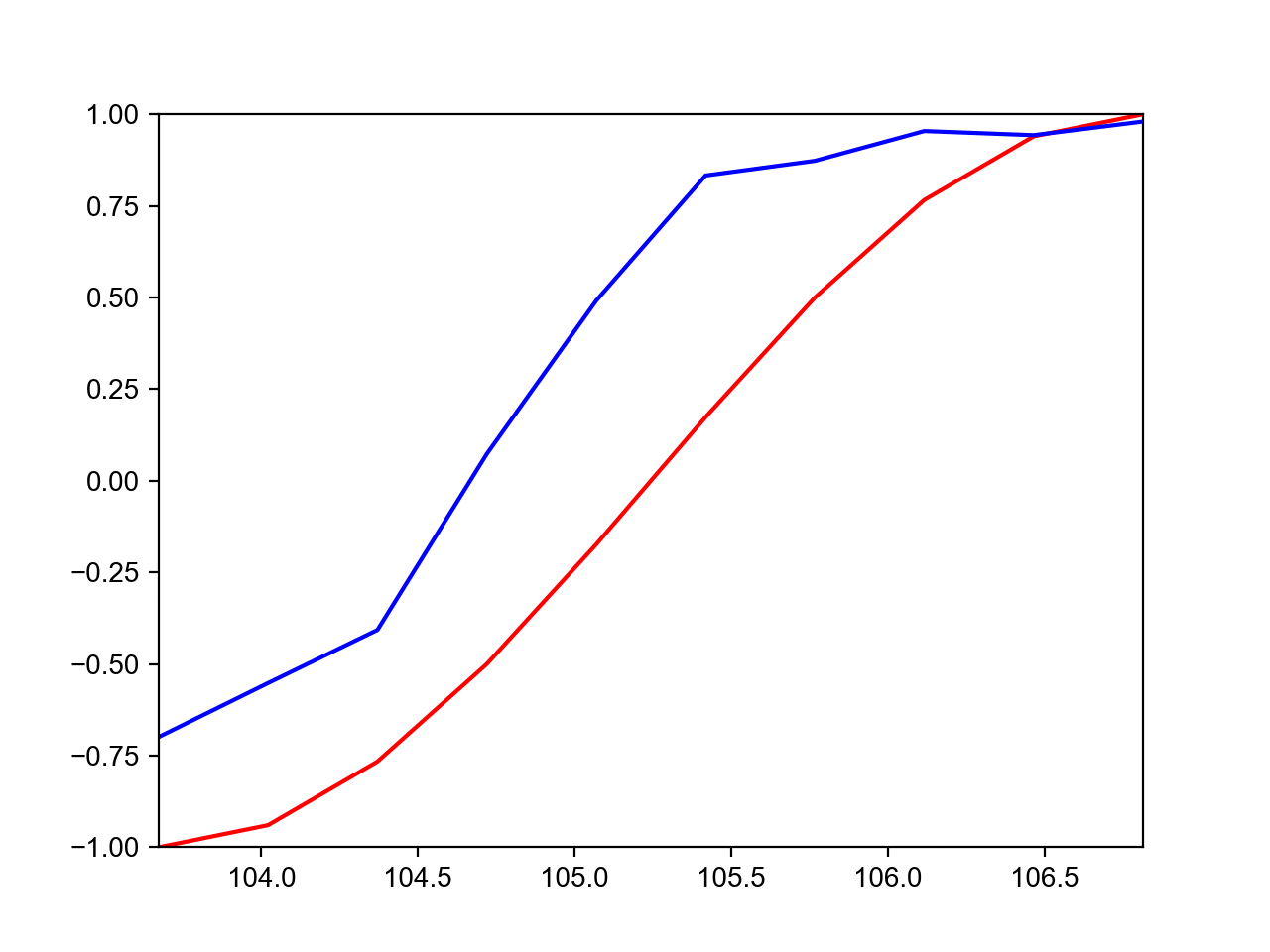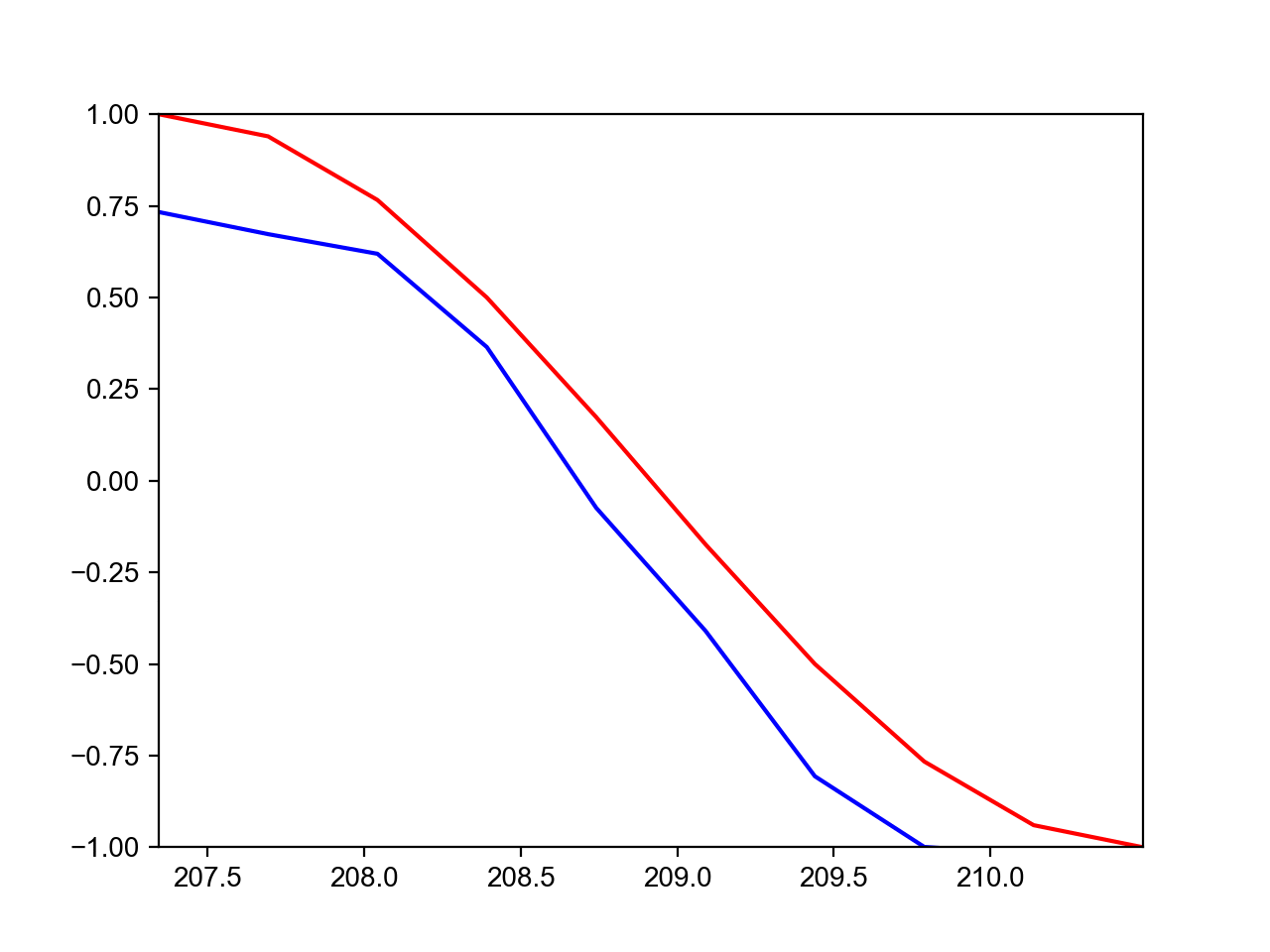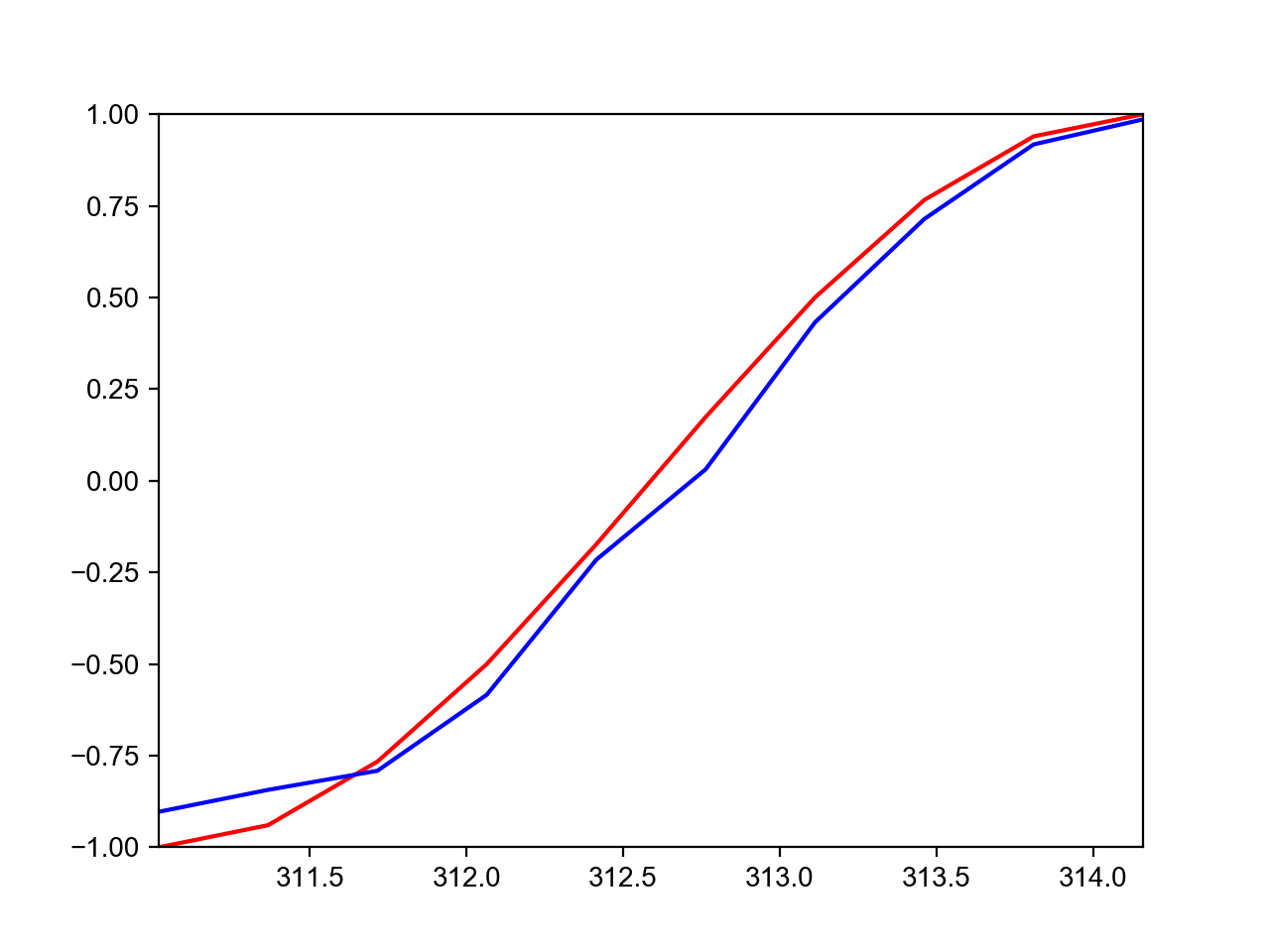
最后放一个当TIME_STEP分别等于10和20的最终预测结果的对比图:
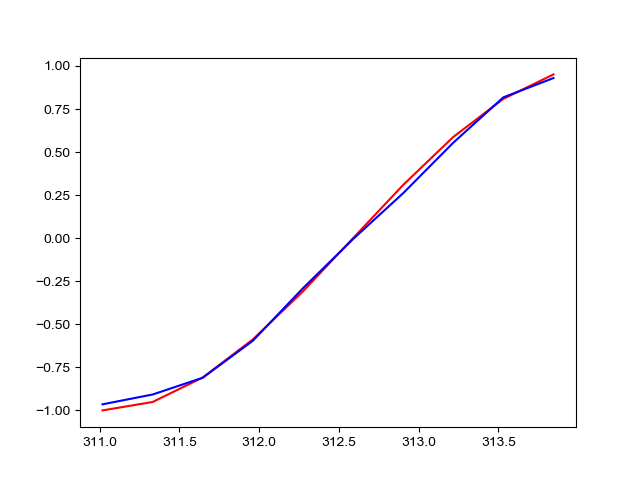
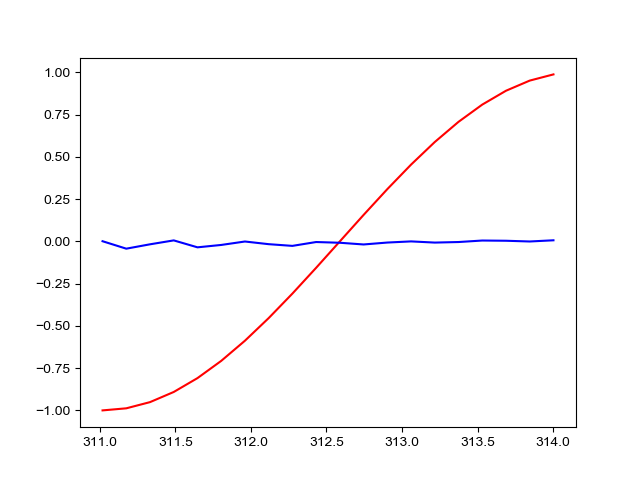
第一张是TIME_STEP=10的预测结果,第二张是TIME_STEP=20的预测结果。为什么当TIME_STEP=20的预测结果差得十万八千里呢?
这是因为经典的RNN存在梯度爆炸和梯度弥散问题(我尝试修剪了梯度可是结果还是很差,不知道是不是其它原因),对长时序的预测表现很不好,所以才有了后来的LSTM和GRU等RNN变种。实际现在已经很少使用经典RNN了。有时间在说说LSTM吧,欢迎关注!